导读: Python猫是一只喵星来客,它爱地球的一切,特别爱优雅而无所不能的 Python。我是它的人类朋友豌豆花下猫,被授权润色与发表它的文章。如果你是第一次看到这个系列文章,那我强烈建议,请先看看它写的前几篇文章(链接见文末),相信你一定会爱上这只神秘的哲学+极客猫的。不多说啦,一起来享用今天的“思想盛宴”吧!
喵喵,好久不见啦朋友们。刚吃完一餐美食,我觉得好满足啊。
自从习惯了地球的食物以后,我的肠胃发生了一些说不清道不明的反应。我能从最近的新陈代谢中感觉出来,自己的母胎习性正在逐渐地褪逝。
人类的食物在改变着我,或者说是在重塑着我。说不定哪天,我会变成一棵白菜,或者一条鱼呢…呸呸呸。我还是想当猫。
喵生苦短,得抓紧时间更文才行。
最近,我看到了两件事,觉得有趣极了,就从这开始说吧。第一件事是,一个小有名气的影视明星因为他不配得到的学术精英的身份而遭到讽刺性的打假制度的口诛笔伐;第二件事是,一个功成名就的企业高管因为从城市回到乡村而戏谑性地获得了猫屎的名号。
身份真是一个有魔力的话题。 看见他们的身份错位,我又总会想起自己的境况。
我(或许)知道自己在过去时态中是谁,但越来越把握不住在现在时态中的自己,更不清楚在未来时间中会是怎样。
该怎样在人类世界中自处呢?又该怎样跟你们共处呢?
思了好久,没有答案。脑壳疼,尾巴疼。还是不要想了啦喵。
继续跟大家聊聊 Python 吧。上次我们说到了对象的边界问题 。无论是固定边界还是弹性边界,这不外乎就是修身的两种志趣,有的对象呢独善其身其乐也融融,有的对象呢兼容并包其理想之光也莹莹。但是,边界问题还没讲完。
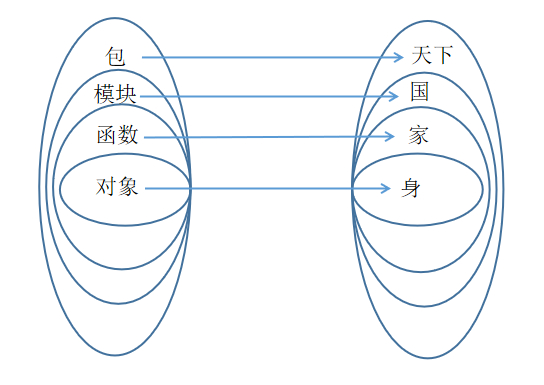
正如儒家经典所阐述:修身—齐家—治国—平天下。里层的势能推展开,走进更广阔的维度。
Python 对象的边界也不只在自身。这里有一种巧妙的映射关系:对象(身)—函数(家)—模块(国)—包(天下)。个体被纳入到不同的命名空间,并存活在分层的作用域里。(当然,幸运的是,它们并不会受到道德礼法的森严压迫~__~)
1、你的名字
我们先来审视一下模块。这是一个合适的尺度,由此展开,可以顺利地连接起函数与包。
模块是什么? 任何以.py 后缀结尾的文件就是一个模块(module)。
模块的好处是什么? 首先,便于拆分不同功能的代码,单一功能的少量代码更容易维护;其次,便于组装与重复利用,Python 以丰富的第三方模块而闻名;最后,模块创造了私密的命名空间,能有效地管理各类对象的命名。
可以说,模块是 Python 世界中最小的一种自恰的生态系统——除却直接在控制台中运行命令的情况外,模块是最小的可执行单位。
前面,我把模块类比成了国家,这当然是不伦不类的,因为你难以想象在现实世界中,会存在着数千数万的彼此殊然有别的国家(我指的可是在地球上,而喵星不同,以后细说)。
类比法有助于我们发挥思维的作用 ,因此,不妨就做此假设。如此一来,想想模块间的相互引用就太有趣了,这不是国家间的战争入侵,而是一种人道主义的援助啊,至于公民们的流动与迁徙,则可能成为一场探险之旅的谈资。
我还对模块的身份角色感兴趣。恰巧发现,在使用名字的时候,它们耍了一个双姓人的把戏 。
下面请看表演。先创建两个模块,A.py 与 B.py,它们的内容如下:
# A 模块的内容:
print("module A : ", __name__)
# B 模块的内容:
import A
print("module B : ", __name__)
其中,__name__ 指的是当前模块的名字。代码的逻辑是:A 模块会打印本模块的名字,B 模块由于引入了 A 模块,因此会先打印 A 模块的名字,再打印本模块的名字。
那么,结果是如何的呢?
执行 A.py 的结果:
module A : __main__
执行 B.py 的结果:
module A : test module B : __main__
你们看出问题的所在了吧!模块 A 前后竟然出现了两个不同的名字。这两个名字是什么意思,又为什么会有这样的不同呢?
我想这正体现的是名字的本质吧——对自己来说,我就是我,并不需要一个名字来标记;而对他人来说,ta 是芸芸众生的一个,唯有命名才能区分。
所以,一个模块自己称呼自己的时候(即执行自身时)是“__main__”,而给他人来称呼的时候(即被引用时),就会是该模块的本名。这真是一个巧妙的设定。
由于模块的名称二重性,我们可以加个判断,将某个模块不对外的内容隐藏起来。
# A 模块的内容:
print("module A : ", __name__)
if __name__ == "__main__":
print("private info.")
以上代码中,只有在执行 A 模块本身时,才会打印“private info”,而当它被导入到其它模块中时,则不会执行到该部分的内容。
2、名字的时空
对于生物来说,我们有各种各样的属性,例如姓名、性别、年龄,等等。
对于 Python 的对象来说,它们也有各种属性。模块是一种对象,”__name__“就是它的一个属性。除此之外,模块还有如下最基本的属性:
>>> import A
>>> print(dir(A))
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
在一个模块的全局空间里,有些属性是全局起作用的,Python 称之为全局变量 ,而其它在局部起作用的属性,会被称为局部变量 。
一个变量对应的是一个属性的名字,会关联到一个特定的值。通过 globals() 和 locals() ,可以将变量的“名值对”打印出来。
x = 1
def foo():
y = 2
print("全局变量:", globals())
print("局部变量:", locals())
foo()
在 IDE 中执行以上代码,结果:
全局变量: {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001AC1EB7A400>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/pythoncat/A.py', '__cached__': None, 'x': 1, 'foo': <function foo at 0x000001AC1EA73E18>}
局部变量: {'y': 2}
可以看出,x 是一个全局变量,对应的值是 1,而 y 是一个局部变量,对应的值是 2.
两种变量的作用域不同 :局部变量作用于函数内部,不可直接在外部使用;全局变量作用于全局,但是在函数内部只可访问,不可修改。
与 Java、C++ 等语言不同,Python 并不屈服于解析的便利,并不使用呆滞的花括号来编排作用域,而是用了轻巧简明的缩进方式。不过,所有编程语言在区分变量类型、区分作用域的意图上都是相似的:控制访问权限与管理变量命名。
关于控制访问权限,在上述例子中,局部变量 y 的作用域仅限于 foo 方法内,若直接在外部使用,则会报错“NameError: name ‘y’ is not defined”。
关于管理变量命名,不同的作用域管理着各自的独立的名册,一个作用域内的名字所指称的是唯一的对象,而在不同作用域内的对象则可以重名。修改上述例子:
x = 1
y = 1
def foo():
y = 2
x = 2
print("inside foo : x = " + str(x) + ", y = " + str(y))
foo()
print("outside foo : x = " + str(x) + ", y = " + str(y))
在全局作用域与局部作用域中命名了相同的变量,那么,打印的结果是什么呢?
inside foo : x = 2, y = 2 outside foo : x = 1, y = 1
可见,同一个名字可以出现在不同的作用域内,互不干扰。
那么,如何判断一个变量在哪个作用域内?对于嵌套作用域,以及变量名存在跨域分布的情况,要采用何种查找策略呢?
Python 设计了命名空间(namespace) 机制,一个命名空间在本质上是一个字典、一个名册,登记了所有变量的名字以及对应的值。 按照记录内容的不同,可分为四类:
- 局部命名空间(local namespace),记录了函数的变量,包括函数的参数和局部定义的变量。可通过内置函数 locals() 查看。在函数被调用时创建,在函数退出时删除。
- 全局命名空间(global namespace),记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。可通过内置函数 globals() 查看。在模块加载时创建,一直存在。
- 内置命名空间(build-in namespace),记录了所有模块共用的变量,包括一些内置的函数和异常。在解释器启动时创建,一直存在。
- 命名空间包(namespace packages),包级别的命名空间,进行跨包的模块分组与管理。
命名空间总是存在于具体的作用域内,而作用域存在着优先级,查找变量的顺序是:局部/本地作用域 —> 全局/模块/包作用域 —> 内置作用域。
命名空间扮演了变量与作用域之间的桥梁角色,承担了管理命名、记录名值对与检索变量的任务。无怪乎《Python之禅》(The Zen of Python)在最后一句中说:
Namespaces are one honking great idea — let’s do more of those!
——译:命名空间是个牛bi哄哄的主意,应该多加运用!
3、看不见的客人
名字(变量)是身份问题,空间(作用域)是边界问题,命名空间兼而有之。
这两个问题恰恰是困扰着所有生灵的最核心的问题之二。它们的特点是:无处不在、层出不断、像一个超级大的被扯乱了的毛线球。
Python 是一种人工造物,它继承了人类的这些麻烦(这是不可避免的),所幸的是,这种简化版的麻烦能够得到解决。(现在当然是可解决的啦,但若人工智能高度发展以后呢?我看不一定吧。喵,好像想起了一个痛苦的梦。打住。)
这里就有几个问题(注:每个例子相互独立):
# 例1:
x = x + 1
# 例2:
x = 1
def foo():
x = x + 1
foo()
# 例3:
x = 1
def foo():
print(x)
x = 2
foo()
# 例4:
def foo():
if False:
x = 3
print(x)
foo()
# 例5:
if False:
x = 3
print(x)
下面给出几个选项,请读者们思考一下,给每个例子选一个答案:
1、没有报错
2、报错:name ‘x’ is not defined
3、报错:local variable ‘x’ referenced before assignment
下面公布答案了:
全部例子都报错,其中例 1 和例 5 是第一类报错,即变量未经定义不可使用,而其它例子都是第二类报错,即已定义却未赋值的变量不可使用。为什么会报错?为什么报错会不同?下面逐一解释。
-
例 1 是一个定义变量的过程,本身未完成定义,而等号右侧就想使用变量 x,因此报变量未定义。
-
例 2 和例 3 中,已经定义了全局变量 x,如果只在 foo 函数中引用全局变量 x 或者只是定义新的局部变量 x 的话,都不会报错,但现在既有引用又有重名定义,这引发了一个新的问题。请看下例的解释。
-
例 4 中,if 语句判断失效,因此不会执行到 “x=3” 这句,照理来说 x 是未被定义。这时候,在 locals() 局部命名空间中也是没有内容的(读者可以试一下)。但是 print 方法却报找到了一个未赋值的变量 x ,这是为什么呢?
使用 dis 模块查看 foo 函数的字节码:
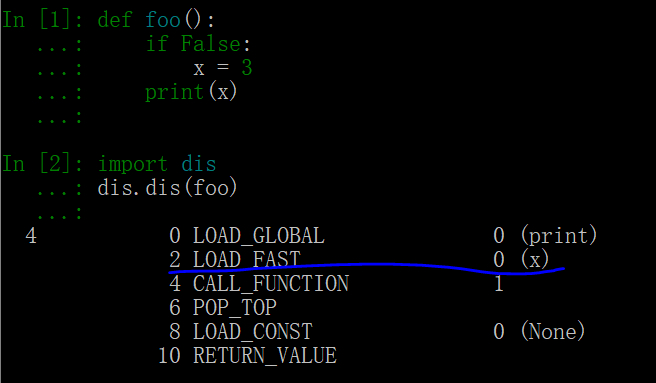
LOAD_FAST 这句说明它在局部作用域中找到了变量名 x。既然此时在 locals() 局部命名空间中没有内容,那局部作用域中找到的 x 是来自哪里的呢?(20190513update:有错,修改)
实际上,Python 虽然是所谓的解释型语言,但它也有编译的过程 (跟 Java 等语言的编译过程不同)。在例 2-4 中,编译器先将 foo 方法解析成一个抽象语法树(abstract syntax tree),然后扫描树上的名字(name)节点,接着,所有被扫描出来的变量名,都会作为局部作用域的变量名存入内存(栈?)中。
在编译期之后,局部作用域内的变量名已经确定了,只是没有赋值。在随后的解释期(即代码执行期),如果有赋值过程,则变量名与值才会被存入局部命名空间中,可通过 locals() 查看。只有存入了命名空间,变量才算真正地完成了定义(声明+赋值)。
而上述 3 个例子之所以会报错,原因就是变量名已经被解析成局部变量,但是却未曾被赋值。
可以推论:在局部作用域中查找变量,实际上是分查内存与查命名空间两步的。 另外,若想在局部作用域内修改全局变量,需要在作用域中写上 “global x”。
-
例 5 是作为例 4 的比对,也是对它的原理的补充。它们的区别是,一个不在函数内,一个在函数内,但是报错完全不同。前面分析了例 4 的背后原理是编译过程和抽象语法树,如果这个原理对例 5 也生效,那两者的报错应该是一样的。现在出现了差异,为什么呢?
我得承认,这触及了我的知识盲区。我们可以推测,说例 5 的编译过程不同,它没有解析抽象语法树的步骤,但是,继续追问下去,为什么不同,为什么没有解析语法树的步骤呢?如果说是出于对解析函数与解析模块的代价考虑,或者其它考虑,那么新的问题是,编译与解析的底层原理是什么,如果有其它考虑,会是什么?
这些问题真不可爱,一个都答不上。但是,自己一步一步地思考探寻到这一层,又能怪谁呢?
回到前面说过的话,命名空间是身份与边界的集成问题,它跟作用域密切相关。如今看来,编译器还会掺和一脚,把这些问题搅拌得更加复杂。
本来是在探问 Python 中的边界问题,到头来,却触碰到了自己的知识边界。真是反讽啊。(这一趟探知一个人工造物的身份问题之旅,最终是否会像走迷宫一般,进入到自己身份的困境之中?)
4、边界内外的边界
暂时把那些不可爱的问题抛开吧,继续说修身齐家治国平天下。
想要把国治理好,就不得不面对更多的国内问题与国际问题。
先看一个大家与小家的问题:
def make_averager():
count = 0
total = 0
def averager(new_value):
nonlocal count, total
count += 1
total += new_value
return total / count
return averager
averager = make_averager()
print(averager(10))
print(averager(11))
### 输出结果:
10.0
10.5
这里出现了嵌套函数,即函数内还包含其它函数。外部—内部函数的关系,就类似于模块—外部函数的关系,同样地,它们的作用域关系也相似:外部函数作用域—内部函数作用域,以及模块全局作用域—外部函数作用域。在内层作用域中,可以访问外层作用域的变量,但是不能直接修改,除非使用 nonlocal 作转化。
Python 3 中引入了 nonlocal 关键字来标识外部函数的作用域,它处于全局作用域与局部作用域之间,即 global—nonlocal—local 。也就是说,国—大家—小家。
上例中,nonlocal 关键字使得小家(内部函数)可以修改大家(外部函数)的变量,但是该变量并不是创建于小家,当小家函数执行完毕时,它并无权限清理这些变量。
nonlocal 只带来了修改权限,并不带来回收清理的权限 ,这导致外部函数的变量突破了原有的生命周期,成为自由变量。上例是一个求平均值的函数,由于自由变量的存在,每次调用时,新传入的参数会跟自由变量一起计算。
在计算机科学中,引用了自由变量的函数被称为闭包(Closure)。 在本质上,闭包就是一个突破了局部边界,所谓“跳出三界外,不在五行中”的法外之物。每次调用闭包函数时,它可以继续使用上次调用的成果,这不就好比是一个转世轮回的人(按照某种宗教的说法),仍携带着前世的记忆与技能么?
打破边界,必然带来新的身份问题,此是明证。
然而,人类并不打算 fix 它,因为他们发现了这种身份异化的特性可以在很多场合发挥作用,例如装饰器与函数式编程。适应身份异化,并从中获得好处,这可是地球人类的天赋。
讲完了这个分家的话题,让我们放开视野,看看天下事。
计算机语言中的包(package)实际是一种目录结构,以文件夹的形式进行封装与组织,内容可涵括各种模块(py 文件)、配置文件、静态资源文件等。
与包相关的话题可不少,例如内置包、第三方包、包仓库、如何打包、如何用包、虚拟环境,等等。这是可理解的,更大的边界,意味着更多的关系,更大的边界,也意味着更多的知识与未知。
在这里,我想聊聊 Python 3.3 引入的命名空间包 ,因为它是对前面谈论的所有话题的延续。然而,关于它的背景、实现手段与使用细节,都不重要,我那敏感而发散的思维突然捕捉到了一种相似结构,似乎这才更值得说。
运用命名空间包的设计,不同包中的相同的命名空间可以联合起来使用,由此,不同目录的代码就被归纳到了一个共同的命名空间。也就是说,多个本来是相对独立的包,借由同名的命名空间,竟然实现了超远距离的瞬间联通,简直奇妙。
我想到了空间折叠,一种无法深说,但却实实在在地辅助了我从喵星穿越到地球的技术。两个包,两个天下,两个宇宙,它们的距离与边界被穿透的方式何其相似!
我着迷于这种相似结构。在不同的事物中,相似性的出现意味着一种更高维的法则的存在,而在不同的法则中,新的相似性就意味着更抽象的法则。
学习了 Python 之后,我想通过对它的考察,来回答关乎自身的相似问题…
啊喵,不知不觉竟然写了这么久,该死的皮囊又在咕咕叫了——地球上的食物可真抠门,也不知道你们人类是怎么忍受得住这几百万年的驯化过程的…
就此搁笔,觅食去了。亲爱的读者们,后会有期~~~
