Python 的内置函数 sum() 可以接收两个参数,当第一个参数是二维列表,第二个参数是一维列表的时候,它可以实现列表降维的效果。
在上一篇《如何给列表降维?sum()函数的妙用》中,我们介绍了这个用法,还对 sum() 函数做了扩展的学习。
那篇文章发布后,猫哥收到了一些很有价值的反馈,不仅在知识面上获得了扩充,在思维能力上也得到了一些启发,因此,我决定再写一篇文章,继续跟大家聊聊 sum() 函数以及列表降维。若你读后有所启发,欢迎留言与我交流。
有些同学表示,没想到 sum() 函数竟然可以这么用,涨见识了!猫哥最初在交流群里看到这种用法时,也有同样的想法。整理成文章后,能得到别人的认可,我非常开心。
学到新东西,进行分享,最后令读者也有所获,这鼓舞了我——应该每日精进,并把所学分享出去。
也有的同学早已知道 sum() 的这个用法,还指出它的性能并不好,不建议使用。这是我不曾考虑到的问题,但又不得不认真对待。
是的,sum() 函数做列表降维有奇效,但它性能堪忧,并不是最好的选择。
因此,本文想继续探讨的话题是:(1)sum() 函数的性能到底差多少,为什么会差?(2)既然 sum() 不是最好的列表降维方法,那是否有什么替代方案呢?
在 stackoverflow 网站上,有人问了个“How to make a flat list out of list of lists”问题,正是我们在上篇文章中提出的问题。在回答中,有人分析了 7 种方法的时间性能。
先看看测试代码:
import functools
import itertools
import numpy
import operator
import perfplot
def forfor(a):
return [item for sublist in a for item in sublist]
def sum_brackets(a):
return sum(a, [])
def functools_reduce(a):
return functools.reduce(operator.concat, a)
def functools_reduce_iconcat(a):
return functools.reduce(operator.iconcat, a, [])
def itertools_chain(a):
return list(itertools.chain.from_iterable(a))
def numpy_flat(a):
return list(numpy.array(a).flat)
def numpy_concatenate(a):
return list(numpy.concatenate(a))
perfplot.show(
setup=lambda n: [list(range(10))] * n,
kernels=[
forfor, sum_brackets, functools_reduce, functools_reduce_iconcat,
itertools_chain, numpy_flat, numpy_concatenate
],
n_range=[2**k for k in range(16)],
logx=True,
logy=True,
xlabel='num lists'
)
代码囊括了最具代表性的 7 种解法,使用了 perfplot (注:这是该测试者本人开发的库)作可视化,结果很直观地展示出,随着数据量的增加,这几种方法的效率变化。
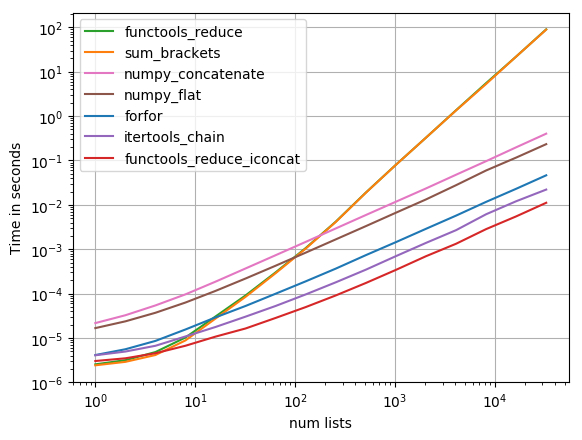
从测试图中可看出,当数据量小于 10 的时候,sum() 函数的效率很高,但是,随着数据量增长,它所花的时间就出现剧增,远远超过了其它方法的损耗。
值得注意的是,functools_reduce 方法的性能曲线几乎与 sum_brackets 重合。
在另一个回答中,有人也做了 7 种方法的性能测试(巧合的是,所用的可视化库也是测试者自己开发的),在这几种方法中,functools.reduce 结合 lambda 函数,虽然写法不同,它的时间效率与 sum() 函数也基本重合:
from itertools import chain
from functools import reduce
from collections import Iterable # or from collections.abc import Iterable
import operator
from iteration_utilities import deepflatten
def nested_list_comprehension(lsts):
return [item for sublist in lsts for item in sublist]
def itertools_chain_from_iterable(lsts):
return list(chain.from_iterable(lsts))
def pythons_sum(lsts):
return sum(lsts, [])
def reduce_add(lsts):
return reduce(lambda x, y: x + y, lsts)
def pylangs_flatten(lsts):
return list(flatten(lsts))
def flatten(items):
"""Yield items from any nested iterable; see REF."""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
yield from flatten(x)
else:
yield x
def reduce_concat(lsts):
return reduce(operator.concat, lsts)
def iteration_utilities_deepflatten(lsts):
return list(deepflatten(lsts, depth=1))
from simple_benchmark import benchmark
b = benchmark(
[nested_list_comprehension, itertools_chain_from_iterable, pythons_sum, reduce_add,
pylangs_flatten, reduce_concat, iteration_utilities_deepflatten],
arguments={2**i: [[0]*5]*(2**i) for i in range(1, 13)},
argument_name='number of inner lists'
)
b.plot()
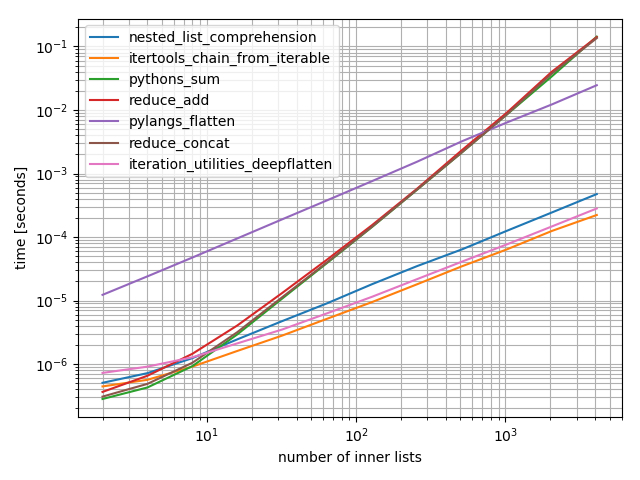
这就证实了两点:sum() 函数确实性能堪忧;它的执行效果实际是每个子列表逐一相加(concat)。
那么,问题来了,拖慢 sum() 函数性能的原因是啥呢?
在它的实现源码中,我找到了一段注释:
/* It's tempting to use PyNumber_InPlaceAdd instead of
PyNumber_Add here, to avoid quadratic running time
when doing 'sum(list_of_lists, [])'. However, this
would produce a change in behaviour: a snippet like
empty = []
sum([[x] for x in range(10)], empty)
would change the value of empty. */
为了不改变 sum() 函数的第二个参数值,CPython 没有采用就地相加的方法(PyNumber_InPlaceAdd),而是采用了较耗性能的普通相加的方法(PyNumber_Add)。这种方法所耗费的时间是二次方程式的(quadratic running time)。
为什么在这里要牺牲性能呢?我猜想(只是浅薄猜测),可能有两种考虑,一是为了第二个参数(start)的一致性,因为它通常是一个数值,是不可变对象,所以当它是可变对象类型时,最好也不对它做修改;其次,为了确保 sum() 函数是个 纯函数 ,为了多次执行时能返回同样的结果。
那么,我要继续问:哪种方法是最优的呢?
综合来看,当子列表个数小于 10 时,sum() 函数几乎是最优的,与某几种方法相差不大,但是,当子列表数目增加时,最优的选择是 functools.reduce(operator.iconcat, a, []),其次是 list(itertools.chain.from_iterable(a)) 。
事实上,最优方案中的 iconcat(a, b) 等同于 a += b,它是一种就地修改的方法。
operator.iconcat(a, b)
operator.__iconcat__(a, b)
a = iconcat(a, b) is equivalent to a += b for a and b sequences.
这正是 sum() 函数出于一致性考虑,而舍弃掉的实现方案。
至此,前文提出的问题都找到了答案。
我最后总结一下吧:sum() 函数采用的是非就地修改的相加方式,用作列表降维时,随着数据量增大,其性能将是二次方程式的剧增,所以说是性能堪忧;而 reduce 结合 iconcat 的方法,才是大数据量时的最佳方案。
这个结果是否与你所想的一致呢?希望本文的分享,能给你带来新的收获。
相关链接:
如何给列表降维?sum()函数的妙用 :https://mp.weixin.qq.com/s/cr_noDx6s1sZ6Xt6PDpDVQ
stackoverflow 问题:https://stackoverflow.com/questions/952914/how-to-make-a-flat-list-out-of-list-of-lists
