前不久,我写了一篇《Fabric教程》,简单来说,它是一个用 Python 开发的轻量级的远程系统管理工具,在远程登录服务器、执行 Shell 命令、批量管理服务器、远程部署等场景中,十分好用。
Fabric 2 是其最新的大版本,跟早前的 Fabric 1 有挺大的不同,更加好用了,但是没填上的坑也挺多的……
本文继续来聊聊 Fabric,不过我不想再面面俱到了,而是专注于这一个话题:它是如何实现对批量服务器的串行/并发管理的?
(友情提示:为了有更好的阅读体验,如果你还不了解 Fabric 的基础用法,建议先阅读前面的教程。)
Fabric 通过 Group 来组合多台服务器。区别在于由 fabric.group.Group 基类(父类)派生出的两个子类:
- SerialGroup(*hosts, **kwargs):按串行方式执行操作
- ThreadingGroup(*hosts, **kwargs):按并发方式执行操作
下面先看看这个基类:
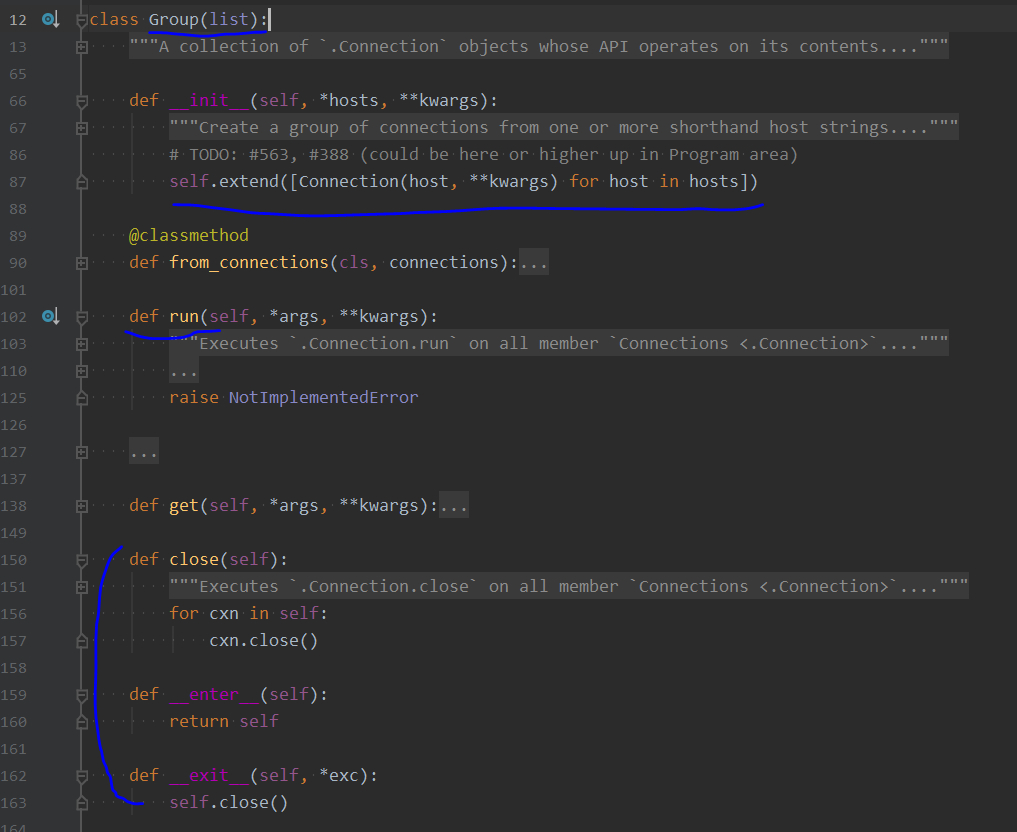
我把一些没用的信息折叠了,比较值得注意的内容有:
- Group 继承了 list,所以能够 extend() ,对传入的服务器分别建立 connection
- 核心的 run() 方法没有写实现,用意是留给子类再实现
- 最后的 __enter__() 和 __exit__() 实现了上下文管理器
有了这个基类,接下来就要看 SerialGroup 和 ThreadingGroup 的具体实现了。
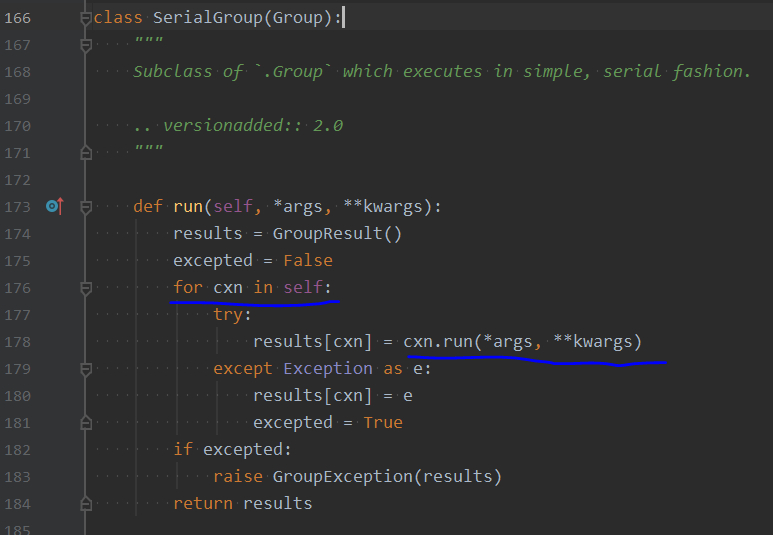
SerialGroup 类很简单,只实现了一个 run() 方法。因为类在初始化时为所有 host 建立了连接而且存了起来,所以这里只需用 for 循环依次取出,再执行 Connection 的 run() 方法。
这里可以看到一种非常实用的开发技巧: 创建类时,让它继承内置的数据结构(如 list、dict), 这样可以直接使用 self.append()、self.extend()、self.update() 等方法把关键的信息存到“自身”,再到取出时则“for xxx in self”,这样就免了创建临时的 list 或 dict,也免得要在参数中传来传去。
GroupResult 和 GroupException 是对执行结果和异常的处理,不是我们关注的重点,这里略过。
接下来看看 ThreadingGroup,它也只有一个 run() 方法:
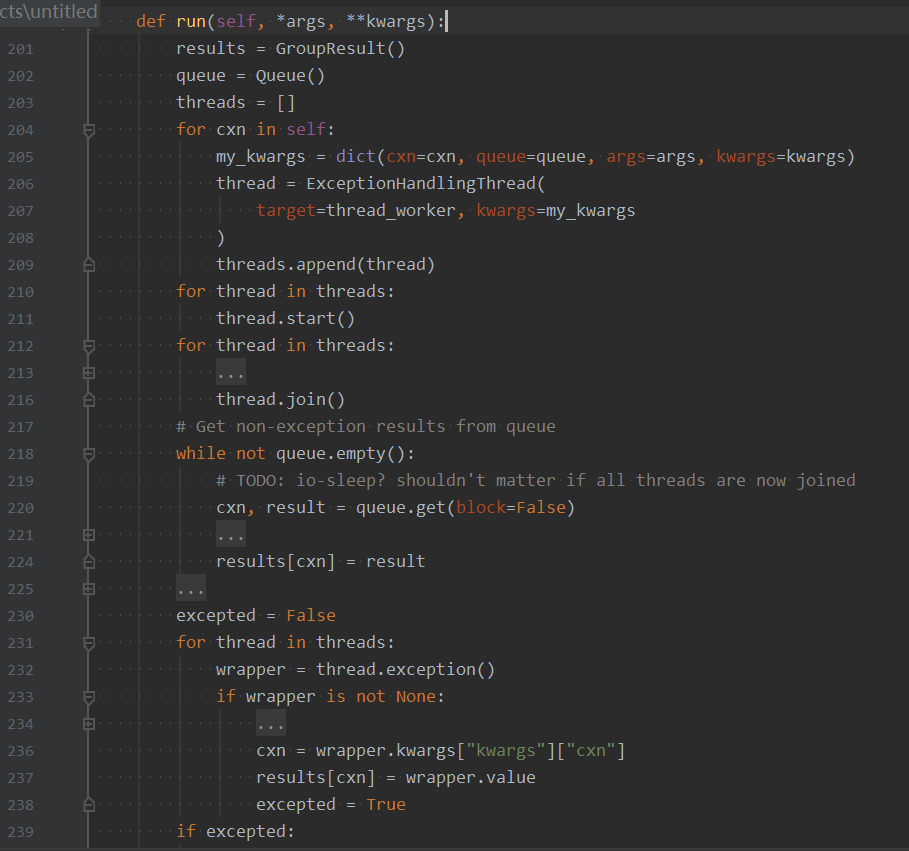
ExceptionHandlingThread 是一个继承了 threading.Thread 的类,这是一种创建多线程的方式。每个线程执行的方法主要做两件事:执行 connection 的 run() 方法,以及将执行成功的结果存入队列中。

接下来再分别把执行成功的结果与出异常的结果都存入到 results 中。
所以,Fabric 是使用了 threading 多线程的方式来实现并发。网络请求是 IO 密集型的,使用多线程是不错的方式。
至此,对于我们在开头提的问题,就有了一个初步的答案:Fabric 封装了两种 Group 来批量管理服务器,其中串行方式就是用了简单的 for 循环,而并发方式使用了 threading 多线程方式。
但是,通过分析这两种 Group 的实现代码(以及使用的实践),我们也可以发现 Fabric 的缺陷:
- Group 只实现了 run() 方法,但是 Connection 的 put()、get()、sudo() 等方法都没有,这意味着用这种方式管理服务器集群时,只能在上面执行 shell 命令……
- 每次调用 run() 方法时,它要等所有主机都执行完,才会返回结果,这意味着先执行完的主机会被阻塞。更为致命的是,如果其中一台主机执行时出了异常,整个 run() 方法就抛异常,这意味着每次使用 run() 方法时,都需要作异常捕获
- run() 方法支持执行单条 shell 命令,但是命令的状态不会传递。假设先在一个 run() 方法中运行 cd 命令切到 A 目录(非根目录),再在下一个 run() 方法创建一个文件,最终结果是该文件并不在 A 目录,而是在默认目录。解决办法是用“&&”连接起多条命令,略显麻烦
这几个问题在 Fabric 的 Github issue 中,被不同的人反复提出,但是还没有得到很好的回应……
言归正传,本文主要分析了 Fabric 在批量管理服务器时的实现方案,阅读其源码,可以了解到串行/并发典型场景的用法,以及类定义、类继承、多线程、异常处理等内容,最后,我们还揭示出了它的几个特性缺陷。
感谢阅读。最后,附上 Fabric 教程:https://mp.weixin.qq.com/s/UHtPaxO2ojql5ps4hTn3Vg
